Loop Engineering + ICM aren't a duo. They're one machine.
Someone in here asked a sharp question this week: are Loop Engineering and ICM a perfect match, or two completely different things?
Neither. They're one machine people keep mistaking for two.
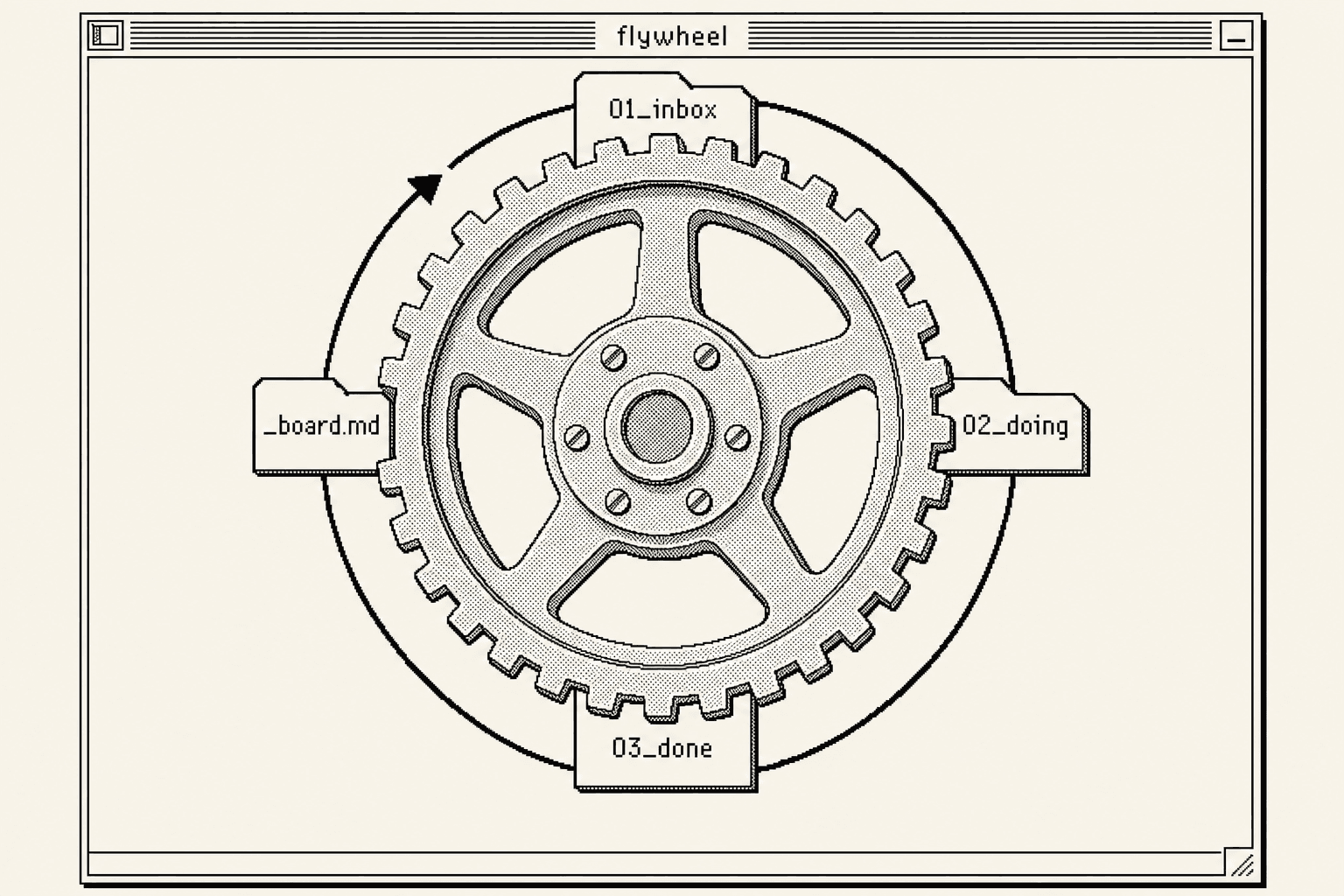
Here's the split everyone starts with, and it isn't wrong: Loop Engineering = how the agent acts. The autonomous cycle of execute, verify, self-correct. ICM = where the agent lives. Transparent folders and markdown that hold the context.
But "where it lives" is carrying way more weight than it gets credit for. A folder structure isn't storage. It's the loop's memory between iterations.
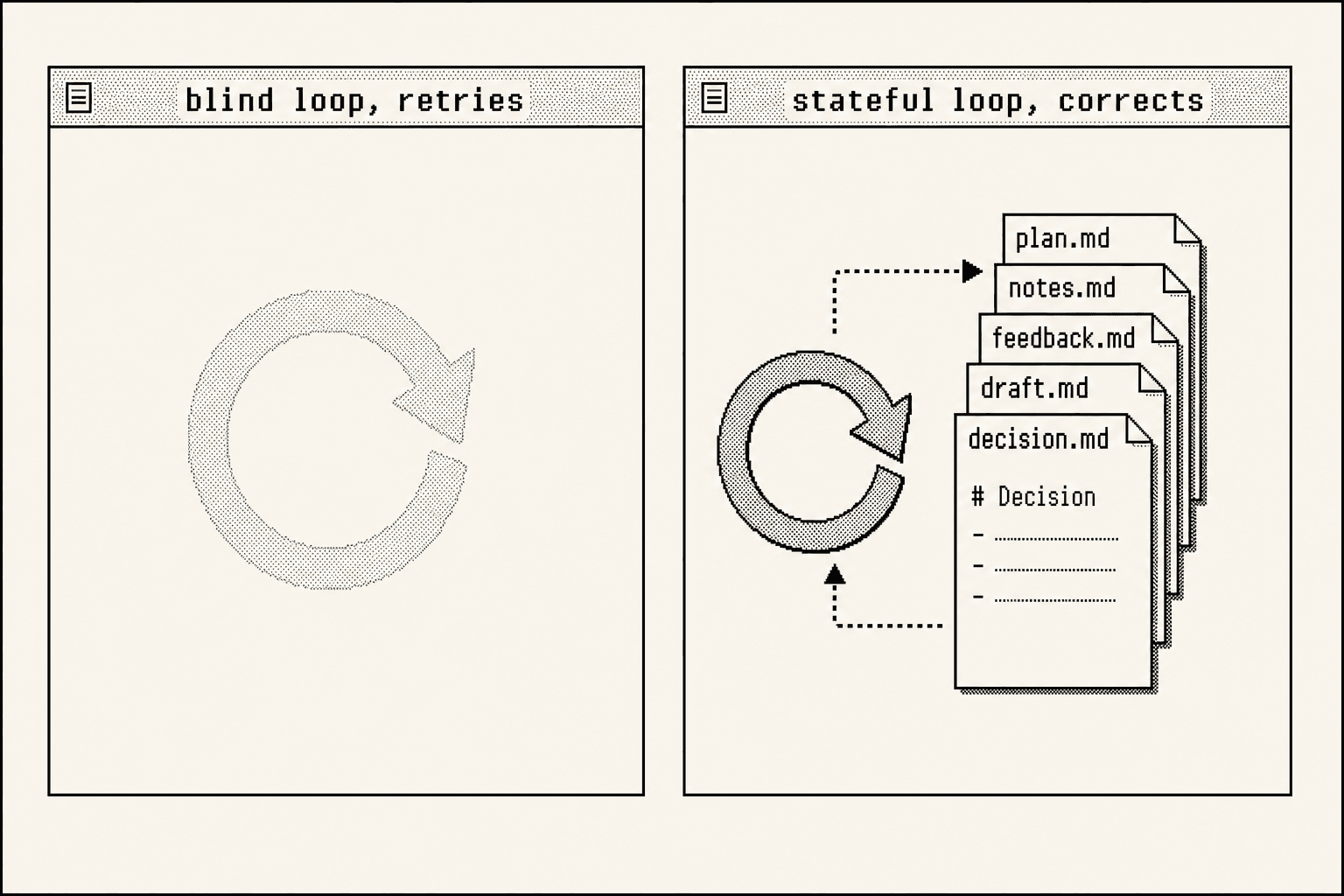
Think about what "self-correct" actually requires. A loop corrects by reading state, acting, then re-reading what changed. If that state only exists in the model's context window, it evaporates the moment the loop restarts or the window rolls over. If it lives on disk as plain readable markdown, the loop can check itself against it on every single pass, forever.
So the whole relationship collapses into one line:
A loop can't verify what it can't read back.
ICM is the thing it reads back. That was always the connection. It was never two tools.
Let me kill the three framings from the original question:
1. "Do they intertwine?" Not as a duo. As one organism. The loop is the metabolism. ICM is the body. Run a loop on a messy structure and it doesn't degrade slowly, it degrades faster, just more legibly.
2. "Can Loop Engineering be the framework FOR ICM?" Flip the arrow. Moving a file from 01_inbox to 02_processing isn't the loop driving ICM. It's the loop using ICM as its scoreboard. The folder a file sits in IS the loop's current state. Moving it is the loop committing a decision it can audit on the next pass.
3. "Or are they for completely different use cases, automation vs human-readable?" That's the exact split you want to collapse, not protect. The whole point of transparent folders is that the autonomous loop AND the human read the same files. That's what lets you stay ON the loop instead of IN it. Delete the transparency and you're back to babysitting a black box.
Not magic, to be clear. ICM doesn't make the loop smart. It makes the loop's mistakes recoverable. I still read the board every time.
Here's the build-it-today version. Five things in a folder:
01_inbox/ new work lands here
02_doing/ loop pulls ONE item here and works it
03_done/ loop moves it here once it verifies
_board.md loop rewrites this every pass, status of everything
_needs_me.md loop parks anything it's unsure about
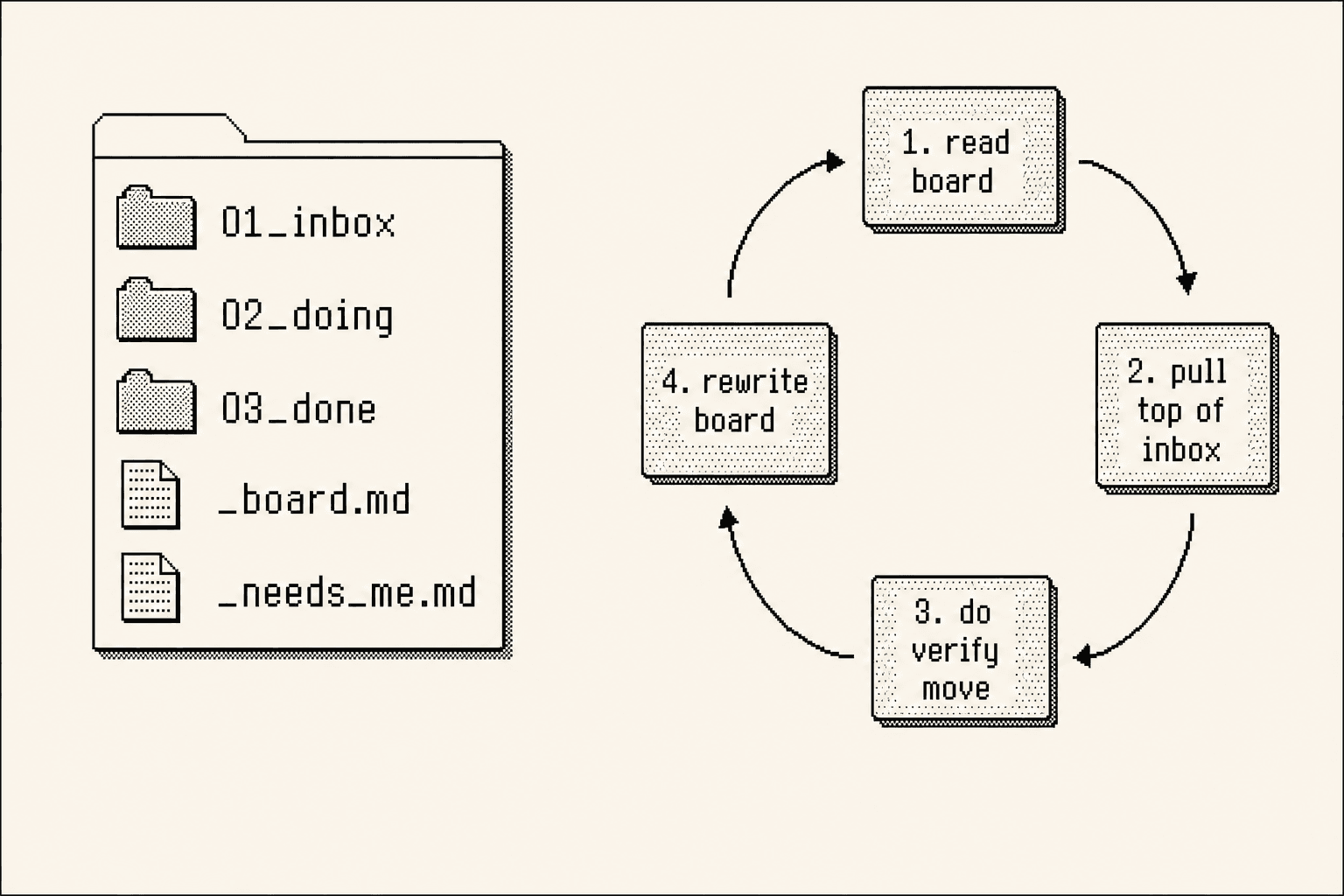
And the loop rule, four lines: read _board.md, then pull the top of 01_inbox into 02_doing, then do it, verify it, move it to 03_done (or _needs_me), then rewrite _board.md and go again.
That's the whole thing. The folders are the state. The loop is the cycle that reads and writes that state. You never watch it run. You read _board.md, the same file the loop writes. That is Loop Engineering and ICM being the same machine.
# _board.md status: 0/3 complete loop_pass: 0 ## 01_inbox (3) - generate hero image - write alt text - compress assets ## 02_doing (0) (empty) ## 03_done (0) (empty)
The law underneath all of it:
An autonomous loop is only as smart as the state it can read back between iterations.
Stateless loops don't correct. They just retry. ICM is the state. You don't get to pick one.
Question back to the room: where do you draw the line on what your loop is allowed to WRITE vs only READ? That boundary is exactly where my loops either earn trust or lose it.
//A<3
↓Loop + ICM starter kit (markdown)