I run 100-agent workflows on a budget model. Here's the catch.

Last night I dispatched 235 agents to review a codebase. The model wasn't Claude.
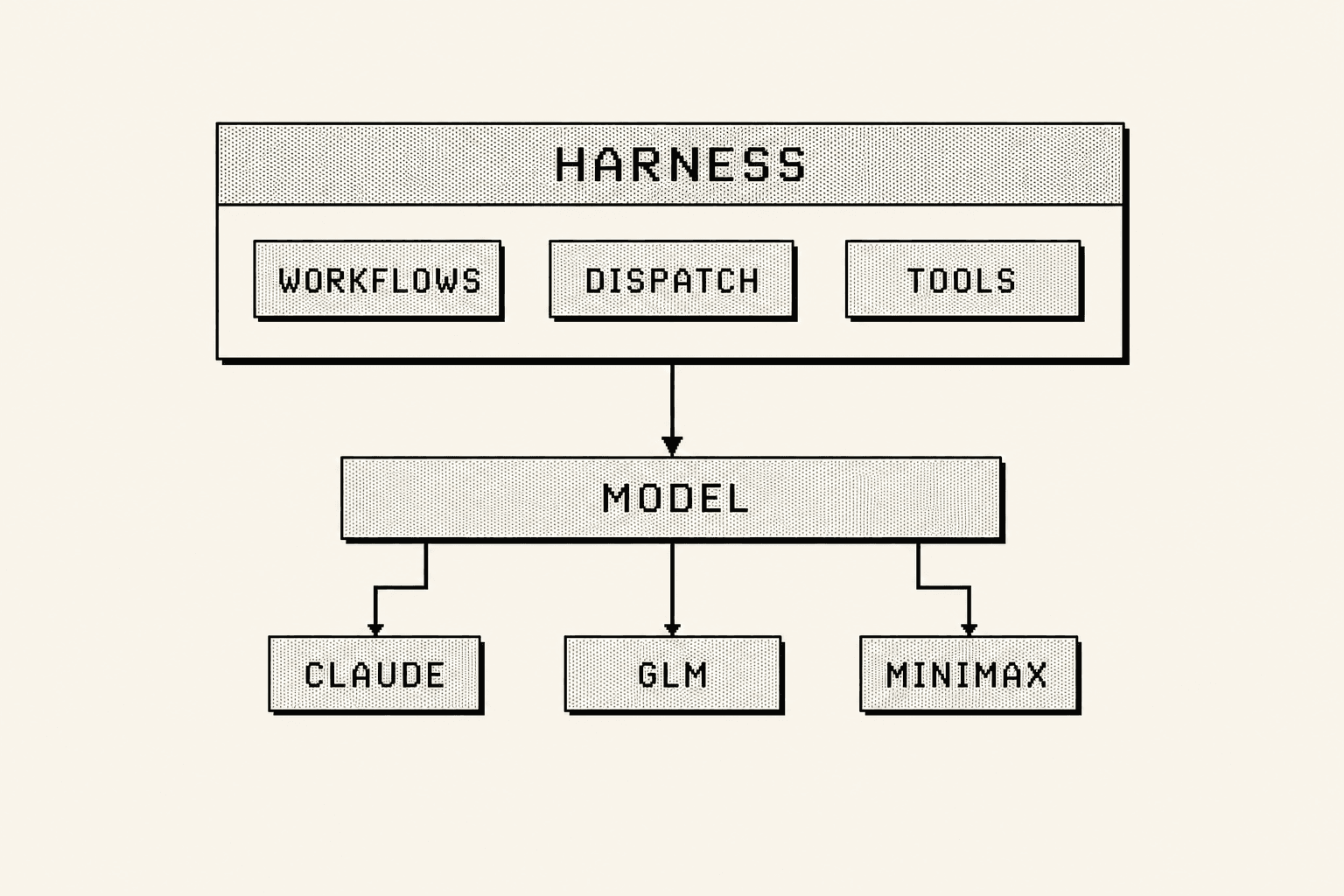
The harness was. Claude Code ran the whole thing. The model underneath was a budget one.
Here is the thing nobody tells you about dynamic workflows. They are not a model feature. They are a harness feature.
Claude Code has a mode called UltraCode, and UltraCode runs the dynamic workflows for you. Turn it on and it fans out tens or hundreds of agents by default, runs them in parallel, verifies each finding adversarially, then synthesises the survivors. That whole dance is orchestration Claude Code performs. The model just fills the seats.
Which is also a cost bomb. Automatic fan-out to hundreds of agents on a premium model is a serious bill arriving by default.
So I started renting the conductor and swapping the orchestra.
The conductor is Claude Code, the harness: UltraCode, dynamic workflows, dispatch, the fan-out and verify loop. That stays fixed. The orchestra is the model underneath, and the model is swappable. Claude is one player you could seat. GLM and MiniMax are others. Point the same harness at a cheaper provider, GLM or MiniMax, and you keep the orchestration while the token bill collapses. Same UltraCode, same automatic dynamic workflows, a fraction of the bill. You utilise the same UltraCode, you just stop paying premium rates to run it.
Now the catch, because there is one.
You do not get all the benefits. A cheaper model reasons worse per agent. One GLM agent is not one Opus agent. What you are buying is the right to run fifty of them for the price of one, and to let structure do the work the raw model cannot.
That is the trade. Depth per agent goes down. Breadth goes way up. And the workflow shape, fan-out then adversarial verify then synthesise, claws most of the quality back, because three cheap sceptics catch what one of them misses.
The numbers from one run:
- 235 agents, fanned out across the workflow.
- 13.12 million tokens between them.
- On premium token rates, that is a serious bill. On the budget orchestra it was a fraction of it, roughly a tenth.
- Same workflow. Same fan-out. Same verify pass.
The orchestra (model)
Agents in the fan-out: 235
Real published rates, Jun 2026 ($/1M in/out): Claude (Opus 4.8) $5/$25, GLM-4.6 $0.43/$1.74, MiniMax M2 $0.26/$1.00. Assumes ~56k tokens per agent (45k in, 11k out).
What you can build today:
- Turn on UltraCode. You do not hand-build the dynamic workflows, UltraCode runs them for you, fanning out the fan-out then verify then synthesise shape by default.
- Point Claude Code at a budget model, GLM or MiniMax. This is the move that lets you utilise UltraCode without the premium bill.
- Run the same UltraCode workflows and watch the structure carry the cheap model.
The sceptic's objection is fair, so I will say it plainly. This is not magic and it is not free. I still review everything. The cheap model still gets things wrong. But the unit economics of being wrong cheaply, in parallel, then voting on the survivors, beat being right expensively, alone.
The principle that outlives the tool:
The orchestration is the intelligence. The tokens are a line item.
Configure the conductor once. Hire whichever orchestra you can afford.